
AI Agent trained to beat humans in a card game
In this project, I developed a game simulation in Python to uncover the optimal strategy for maximizing the score in a unique online card game called Blitz21. This project combined elements of game theory, probability, and artificial intelligence, and computer vision to tackle the challenge.
The challenge
Blitz21 is an online competitive card game where 2 players aim to outscore each other by strategically placing cards from a standard 52-card deck into one of four stacks. The goal is to reach a stack value of 21 without exceeding it.
The game ends when a player busts (exceeds 21) three times. Players score points by creating stacks of 21, making 5-card stacks, and using wild cards. The aim is to achieve the highest score possible while playing faster and smarter than the opponent.
Game Rules and Python Simulation
In this phase, I focused on accurately translating the game rules of Blitz21 into a Python environment.
This involved dealing with the complexities of the game, such as handling special cards (Jack of Spades and Jack of Clubs as wild cards, flexible values for Aces), scoring mechanisms, and the game-ending condition. The challenge was to create a simulation that faithfully represented these rules and allowed for effective training of the AI agent.
Statistical Strategy and Optimization
I explored various game theory methods for card games and decided on the Monte Carlo method. This approach simulates placing a card in a stack and then uses the probabilities of the remaining cards to determine the optimal placement based on simulating the remainder of the game.
The goal was to see if a Monte Carlo approximation could outperform the average player by aiming for the highest score possible, simply by considering the probabilities of the remaining cards without using AI.

After implementing the Monte Carlo method, I found that it worked quite well right out of the box. Based on my experience, it would likely beat a very beginner level player. This approach provided a solid foundation for further optimization and refinement and showed promise for this project.

Evaluation of Existing ML/AI Strategies
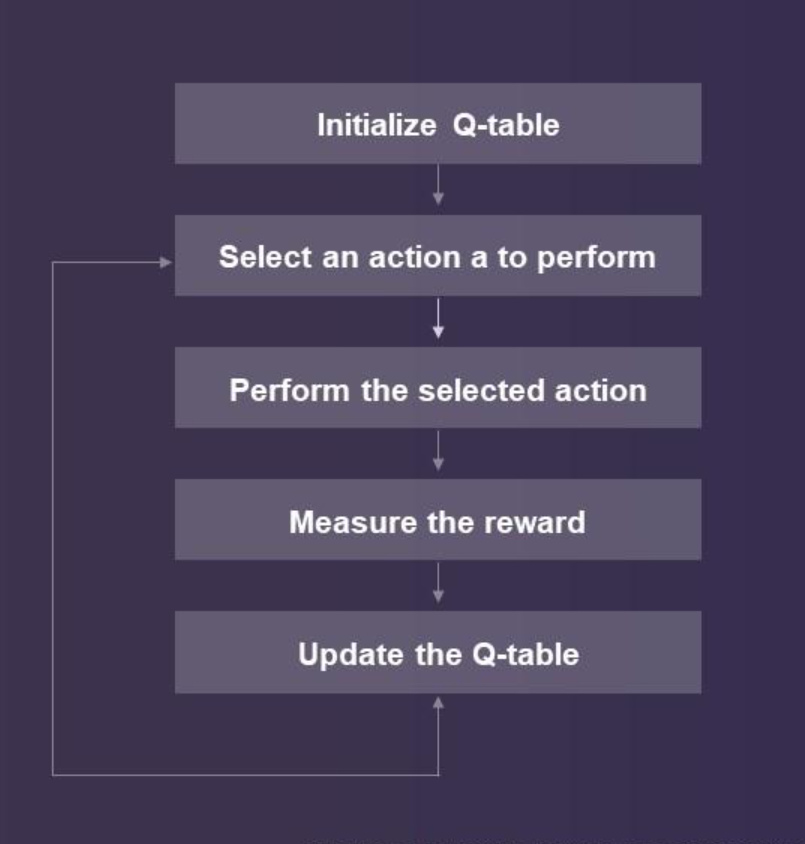
I evaluated existing video game AI agents and the strategies they employed, such as Proximal Policy Optimization (PPO), reinforcement learning, and value iteration. After careful consideration, I decided to utilize Deep Q Learning for this project.
Deep Q Learning was deemed the best choice due to its ability to handle the game's complexity and optimize the agent's strategy by learning from its actions and the resulting outcomes.
Card Detection, Android Emulation, and GUI Control
Initially, I experimented with using image templates to detect cards, but this approach proved unreliable due to the movement of the cards. I ultimately decided to use Optical Character Recognition to read the values of the cards and implemented two image preprocessing pipelines to accurately determine the card and it's color.
This involved typical image processing techniques using the open source Optical Character Regocnition (OCR) Tesseract library and python's CV2. The techniques I used included thresholding to separate the foreground from the background, noise reduction to eliminate unwanted variations when cards were in motion, and contour detection to locate the shapes of the cards.
I limited the OCR to detect only a specific subset of characters relevant to the game, which boosted the accuracy as well. The Android emulator used for this project was Bluestacks, which facilitated having an Android environment on my PC and PyAutoGUI was used for mouse control and clicking within the emulator.
Deep Q Learning Implementation and Performance
Implementing the Deep Q Learning agent was a key phase of this project, focusing on training the AI to match and sometimes exceed the skill level of the average player.
This involved delving into machine learning topics such as neural network architecture, experience replay, and exploration vs. exploitation strategies. One of the more challenging factors I faced was tuning the model's hyperparameters, and learning about the balancing trade-off between learning speed and stability, and ensuring the agent could adapt to different game scenarios.
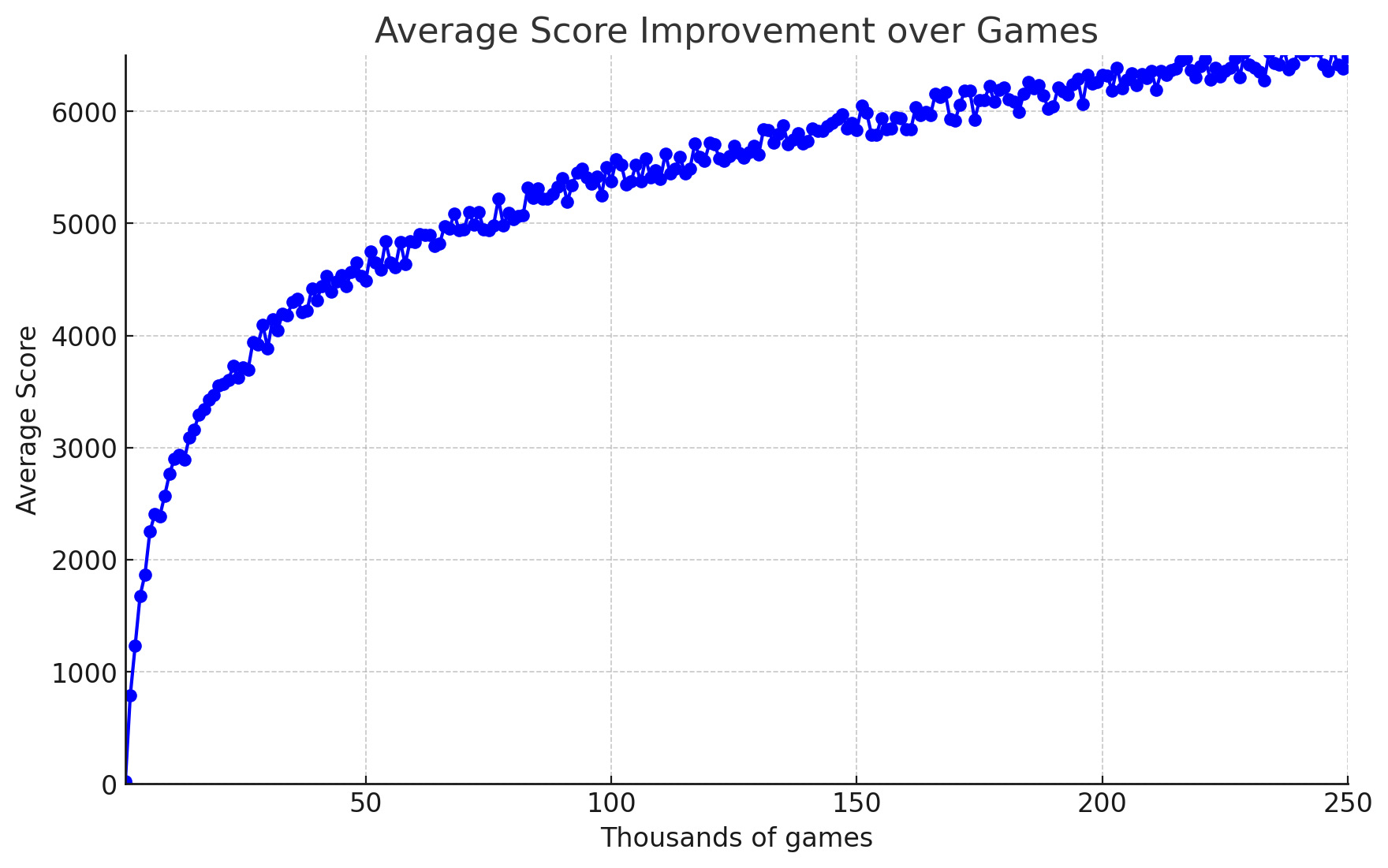
Through research and experimentation, I achieved a logarithmic improvement curve for my agent and learned how to effectively implement and optimize the Deep Q Learning algorithm, resulting in an AI agent capable of making strategic decisions and achieving high scores equivilent to a human player.
Ethical Considerations and Terms of Service
The AI agent developed in this project was able to match or sometimes exceed the skill level of the average player. As someone who enjoyed playing Blitz21 in college, this project was a fascinating exploration of what it takes to create an AI agent capable of competing at a high level.
However, it's important to note that using such software is against the terms of service of many games, and it was never used in paid/money games.
Project outcomes
This project was a valuable learning experience, exposing me to new technologies like game theory, Monte Carlo simulations, and OCR. I gained insights into AI development and the importance of ethical considerations.
To prevent misuse, the source code and trained agent will not be published.